Stable Diffusion系列
详细描述stable diffusion各个版本的模型以及其区别
| SD 1.5 | SD 2.1 | SDXL | SD3 | FLUX-1.0 | |
|---|---|---|---|---|---|
| 模型架构 | UNet | UNet | UNet(Base+Refiner) | MM-DiT | MM-DiT |
| Text-Encoder | CLIP ViT-L/14 | CLIP ViT-H/14 | CLIP ViT-L/14 + OpenCLIP ViT-bigG/14 | CLIP ViT-L/14 + OpenCLIP ViT-bigG/14 + T5-XXL | CLIP ViT-L/14 + T5-XXL |
| VAE compression ratio | 8 | 8 | 8 | 8 | 8 |
| 训练目标 | Epsilon-prediction | Epsilon-prediction(SD2.1-base)/ v-prediction(SD2.1-v) | Epsilon-prediction | Rectified Flow | Rectified Flow |
Stable Diffusion中为什么Context Embedding用来生成K和V,Latent Feature用来生成Q?
因为在Stable Diffusion中,主要的目的是想把文本信息注入到图像信息中里,所以用图片token对文本信息做 Attention实现逐步的文本特征提取和耦合。
CFG guidance scale的作用
guidance_scale代表CFG(Classifier-free guidance)的权重,当设置的guidance_scale越大时,文本的控制力会越强,SD模型生成的图像会和输入文本更一致。通常guidance_scale可以设置在7-8.5之间,就会有不错的生成效果。如果使用非常大的guidance_scale值(比如11-12),生成的图像可能会过饱和,同时多样性会降低。
Stable Diffusion中的Negative prompt中的作用
Negative prompt对应无条件扩散模型的文本输入,在训练时设置为空字符串,在推理时设置为我们不想要生成的内容,改善图像生成效果。
SDXL的架构与SD2.1的区别
SDXL是一个两阶段的级联扩散模型,包括base模型和refiner模型,其中base模型与SD2.1基本一致,refiner模型对base模型生成的图像latent继续进行优化,提升图像质量
MM-DiT
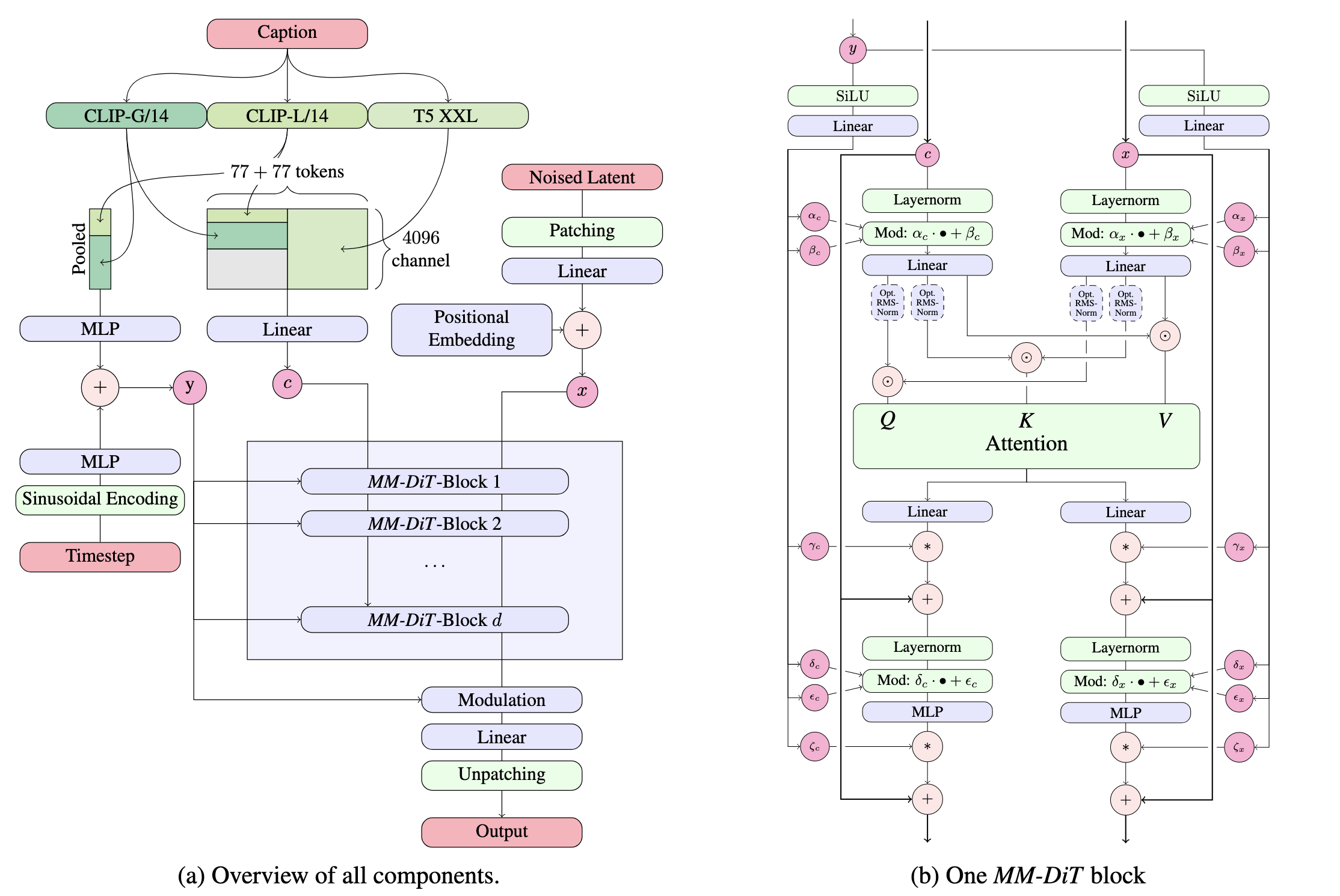
SD2和SD1系列的模型都是用Cross-Attention的形式将文本特征和图像特征结合(文本特征作为keys和values),MM-DiT对文本token和图像latent token分别设置了两套独立的权重参数(文本和图像属于不同的模态),并且在attention计算之前拼接(Concat)在一起,也就相当于用两个独立的Transformer对不同模态的特征进行处理。
Positional Embedding采用Sine-Cosine Encoding
y包括Timestep信息和CLIP pooled embedding(全局语义信息),作为额外的条件信息,通过adaLN-Zero的方式注入MM-DiT中
SD3中的采样方法
SD3不再使用DDPM,而是使用Rectified Flow作为采样方法
$$ x_t=(1-t)x_0+t\epsilon $$
以直线的形式连接噪声和真实数据之间的分布
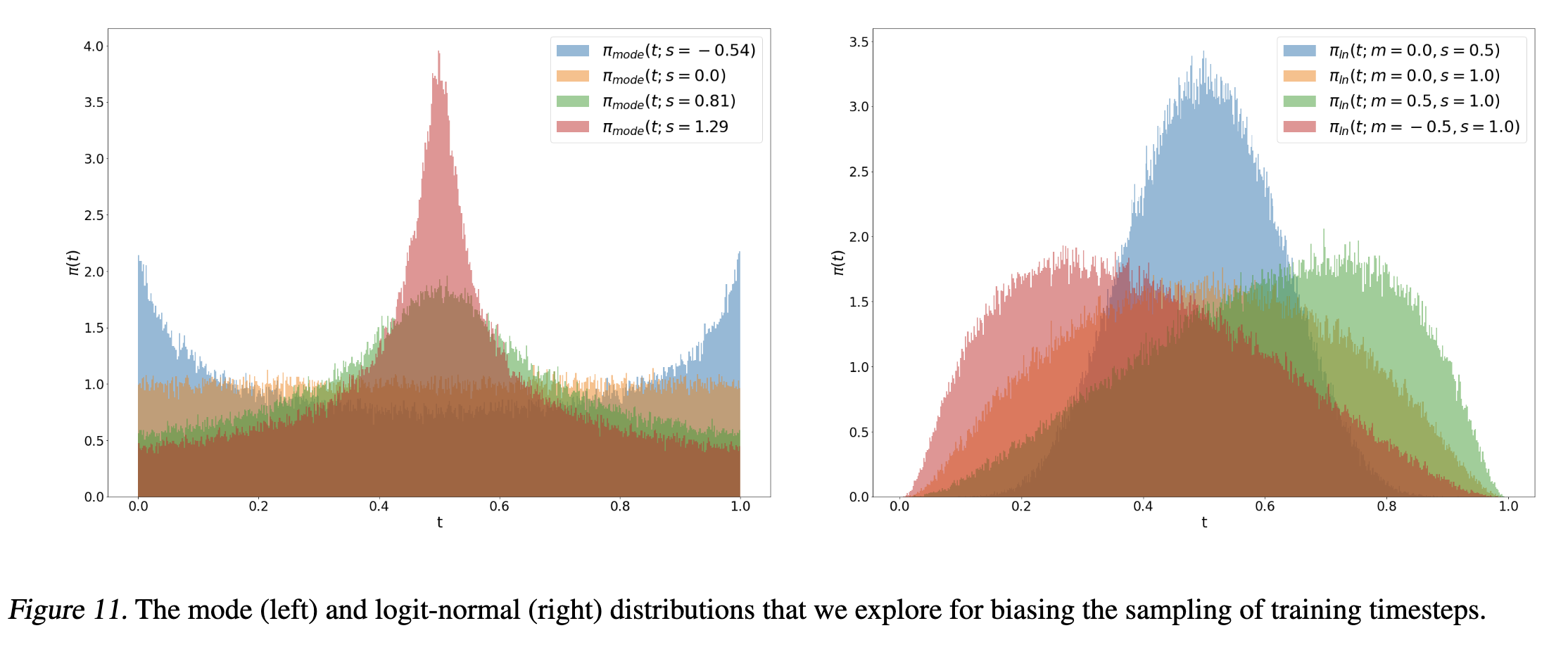
额外的,SD3指出原始的Rectified Flow的时间步在[0,1]上均匀采样,但是不同时间步的任务难度是不一样的:刚开始和快到终点的路线很好学,而路线的中间处比较难学。SD3主要设计了两种方法:Model Sampling with Heavy Tails 和 Logit-Normal Sampling。其中Logit-Normal Sampling的主要问题在于对于t=0和t=1的情况基本采样不到,对性能可能会有一定的影响。
SD3中的DPO和SDXL中的RLHF
DPO(Direct Preference Optimization,直接偏好优化)是SD3采用的一种更高效的对齐技术。
与SDXL使用的RLHF技术(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)相比,DPO技术的优势是无需单独训练一个Reward模型,而是直接基于成对的比较数据进行微调训练。 具体来说,我们首先收集人类偏好数据(固定提示词生成的图片中选出人类最喜欢的那个);然后设计一个损失函数,使模型倾向于生成更符合人类偏好的输出。通过最小化这个损失函数,直接微调模型参数。DPO避免了强化学习中的试错过程,训练更稳定,效率更高。
RLHF是SDXL中采用的一种对齐技术,它需要先训练一个独立的Reward模型来评估生成图像的质量,然后使用强化学习算法(如PPO)来优化扩散模型,使其生成更符合人类偏好的图像。虽然RLHF理论上可以获得更好的对齐效果,但训练过程复杂,需要大量计算资源,且训练不稳定。相比之下,DPO通过直接优化偏好数据,避免了这些问题,成为SD3的首选方案。
SD3的QK Norm
随着SD3的参数量增大,为了混合精度训练的稳定性,SD3采用了RMSNorm对Q,K Embeddings进行Normlization。
1import torch
2import torch.nn as nn
3
4class RMSNorm(nn.Module):
5 def __init__(self, normlized_shape, eps=1e-6):
6 self.normlized_shape = normlized_shape
7 self.eps = eps
8 self.shift = torch.parameters(torch.zeros(norm_shape))
9 self.scale = torch.parameters(torch.ones(norm_shape))
10
11 def forward(self, x):
12 rms_mean = torch.sqrt(torch.means(x**2, dim=-1, keepdim=True))+self.eps
13 x_norm = x/rms_mean
14 return self.scale*x_norm+self.shift
FLUX-1.0
FLUX的Transformer在MM-DiT的基础上增加了single-DiT,先使用MM-DiT block实现两个模态信息融合,然后再接Single-DiT Block加深模型深度,增强模型的整体学习能力的同时,还可以节省一些参数。
FLUX在Single-DiT中引入了并行注意力模块,将注意力层和线性层之间的串联结果变成并联,提高计算的并行度。
LCM-LoRA
LCM-LoRA (Latent Consistency Model - Low-Rank Adaptation) 是一种基于蒸馏技术的快速采样方法,可以将原本需要25-50步的采样过程压缩到2-8步,同时保持较高的图像质量。与SDXL Turbo类似,LCM-LoRA通过一致性蒸馏(Consistency Distillation)训练,但其优势在于以LoRA的形式发布,可以灵活地与各种基础模型和其他LoRA组合使用,而不需要重新训练整个模型。
Qwen Image
Qwen Image主要由三个部分组成:Qwen2.5-VL作为文本编码器提取文本信息, Wan2.1-VAE将图像特征压缩到latent space,扩散模型采用MM-DiT
VAE:Qwen Image采用了Wan-2.1-VAE,将encoder的参数冻结,微调decoder,目的在于使其能够同时兼容图像和视频输入。在训练过程中动态调整感知损失和重建损失的ratio,能够有效减少网格伪影。
MM-DiT:与SD3的结构类似,使用联合注意力同时处理文本和图像特征。不同之处在于Qwen-Image引入了MSRoPE,文本输入被视为2D向量,并且在两个维度上应用相同的位置ID,相当于将文本向量沿图像对角线位置拼接。好处在于能够在图像端利用分辨率缩放优势,同时在文本端保持与1D-RoPE的功能等效性,从而无需确定文本的最佳位置编码。
面试八股文
- 简述DDPM的算法原理:DDPM包括前向加噪和逆向去噪两个过程。前向过程通过不断添加高斯噪声,将原始图像逐步转换为标准高斯分布。逆向过程则学习去噪,从标准高斯分布还原到目标分布,从而实现图像生成。
- 重参数化技巧:VAE中的重参数化$z_i=\mu+\sigma\epsilon, \epsilon\in\mathcal{N}(0,I)$,使得采样过程可导。在DDPM中,利用重参数化技巧基于原始数据 $x_0$对任意 $t$ 步的 $x_t$进行采样, $x_t = \sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon$
- 马尔可夫过程:在给定当前状态的条件下,未来过程的状态只与当前状态有关,而与过去时刻的状态无关。在DDPM中,给定真实图片 $x_0\sim q(x)$,DDPM通过 $T$次加噪得到 $x_1,x_2,…,x_T$,其加噪过程可以视为马尔可夫过程。
- 为什么DDPM加噪过程中,前期加噪少,后期加噪多(对应Noise schedule中 $\bar{\alpha}_t$越来越小):前期如果加的噪声太多,会使得数据扩展得太快,使得逆向还原变得困难,同时因为后期数据已经接近于随机噪声了,后期如果噪声加得不够多,会使得链路变长。
- 变分推断:
- 基本定义:变分推断(Variational Inference)是一种将统计推断问题转化为优化问题的方法。当后验分布难以直接计算时,它寻找一个参数化的简单分布 $q$ 来近似真实后验分布 $p$,通过最小化两者间的 KL 散度(等价于最大化证据下界 ELBO)来求解。
- 核心视角:DDPM 可视为具备固定编码器(前向扩散过程)的变分自编码器(VAE)。
- 目标函数:最大化数据的对数似然 $\log p_\theta(x_0)$ 等价于最大化证据下界(ELBO)。
- 推导结果:优化 ELBO 中的一致性项( $D_{KL}(q(x_{t-1}|x_t, x_0) \parallel p_\theta(x_{t-1}|x_t))$)最终简化为最小化预测噪声与真实噪声的 MSE。
- Stable Diffusion中的Negative prompt中的作用
$$ pred_noise = \epsilon_{\theta}(x_t,t,c)+(1-\omega)\epsilon_{\theta}(x_t,t,c_{neg}) $$
Negative prompt对应无条件扩散模型的文本输入,在训练时设置为空字符串,在推理时设置为我们不想要生成的内容,改善图像生成效果。
简述Diffusion Model和VAE之间的区别和联系:
- 联系:DDPM可以看作是一个特殊的变分自编码器(VAE),其前向扩散过程相当于固定的编码器,逆向去噪过程相当于解码器。两者都通过最大化证据下界(ELBO)来优化模型。
- 区别:VAE通常是单步编码和解码,而Diffusion Model采用多步迭代的方式;VAE的编码器是可学习的,而DDPM的前向过程是固定的马尔可夫链;Diffusion Model通常能生成更高质量的图像,但采样速度较慢。
简述Diffusion Model和GANs之间的区别和联系:
- 联系:两者都是生成模型,目标都是学习数据分布并生成高质量样本。都可以用于图像生成、图像编辑等任务。
- 区别:GANs通过对抗训练(生成器与判别器博弈)学习,而Diffusion Model通过逐步去噪过程学习;GANs采样速度快但训练不稳定,容易出现模式崩塌,而Diffusion Model训练稳定但采样速度较慢;Diffusion Model通常能生成更多样化和高质量的图像,而GANs在某些任务上可能更快但质量不够稳定。
Diffusion Model的Loss: Diffusion model是从低频逐步学习到高频的,在模型训练前期更多是学习数据集中低频分布,此时Loss差异体现较大;但是在模型训练后期更多是学习数据集中的高频分布,此时Loss差异较小,但是在人眼感知层面差异较大。
DiT模型中添加控制条件的方式有哪些?各有什么优缺点?
- In-context conditioning: 将两个Embeddings看成两个tokens合并在输入的tokens中,类似于ViT的Cls token,实现简单,基本上不引入额外的计算量。
- Cross-attention block: 将两个Embeddings拼接成一个序列,然后在transformer block中插入cross-attention block,条件embeddings作为cross attention的key和value。缺点是需要引入额外的计算
- AdaLN: 将time embedding和text embedding相加,回归得到LayerNorm中scale和shift两个参数。
- AdaLN-Zero: 采用zero初始化的adaLN,将adaLN的Linear层参数初始化为zero,这样网络初始化时transformer block的残差模块就是一个identity函数。另外,除了在LN之后回归scale和shift,还在每个残差模块之前回归一个scale。DiT原论文的实验结果表示AdaLN-Zero的效果是最好的。
在Image2Image或Image2Video任务中,如何尽可能保持住输入Image的特征?
- 条件扩散模型:在LDMs中添加Image condition,一般用CLIP提取图像特征,但是CLIP特征对于图像的细节保持很差,常规的优化方法是用DINO替代
- 垫图法:将输入的高斯噪声$x_T$替换为高斯噪声+条件图像,好处是能够保持条件的低频特征,坏处是会很大程度破坏多样性,并且可控性不足
- IP-Adapter:IP-Adapter在原有的Cross-attention计算上增加了image condition $$ Z = Softmax(\frac{QK^T}{\sqrt{d}})V+Softmax(\frac{Q{({K}’)}^T}{\sqrt{d}}){V}' $$
- ControlNet:条件作为controlnet的输入,通过zero-convolution与预训练的神经网络(参数冻结)连接,对于添加controlnet的位置,Encoder和middle部分都不变,只有decoder部分加入controlnet;
- ReferenceNet:用一个结构和原始模型一样的referencenet,在主网络的每一层都与参考网络相连,优势在与能够最大限度地保持原始Image的特征,特征保持能力更强。
现有Diffusion model中常用的采样器,各自有什么特点?
DDPM采样器: DDPM是扩散模型的原始采样器。它模拟一个马尔可夫链的反向过程:每个步骤从$x_t$预测噪声$\epsilon_{\theta}(x_t,t)$,然后计算均值$\mu_\theta(x_t, t)$和方差$\sigma_t^2$,并添加高斯噪声$z \sim \mathcal{N}(0, I)$来采样$x_{t-1}$。噪声方差基于训练时的噪声调度(variance schedule)$\beta_t$或$\alpha_t = 1 - \beta_t$ (一般是$\alpha_t$)。
数学表述(简化为预测噪声形式): $$ x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(x_t, t) \right) + \sigma_t z, \quad z \sim \mathcal{N}(0, I) $$ 其中$\bar{\alpha}_t = \prod_{s=1}^t \alpha_s,\sigma_t = \sqrt{\beta_t}$(或学习方差变体)。 特点是质量高,多样性强,但是速度较慢,需要较多的采样步数
DDIM采样器: 非马尔可夫确定性采样器。它复用DDPM训练的模型,但改变采样轨迹:通过引入超参数$\eta$(通常设为0时确定性)来控制随机性。DDIM允许跳跃式采样(子采样时间步),从噪声直接“直线”路径回到$x_0$,而非严格马尔可夫链。
数学表述: $$ x_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \left( \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}} \right) + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \cdot \epsilon_\theta(x_t, t) + \sigma_t z $$ 其中$\hat{x}_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}}$,$\sigma_t = \eta \sqrt{(1 - \bar{\alpha}_{t-1}) / (1 - \bar{\alpha}_t) \cdot (1 - \bar{\alpha}_t / \bar{\alpha}_{t-1})}$; $\eta=0$时确定性。 特点是高效灵活,并且能够在少步数采样时保持图像高保真质量,缺点是少步可能会积累误差,需要蒸馏训练优化
PLMS(Pseduo Linear Multi-Step): 基于DDIM的伪线性多步方法,模拟线性多步积分器(如Adams方法)。它在DDIM框架下使用历史步骤的线性组合来预测下一个$x_{t-1}$,减少单步误差,提高稳定性。
数学表述:核心是多步线性插值: $$ x_{t-1} = \sum_{k=1}^K w_k \cdot \hat{x}_{t-k+1} + \sigma_t z $$ 其中$\hat{x}$是基于DDIM的预测,$w_k$为线性权重(伪Adams-Bashforth)。通常K=2-3步。
Euler Sampler: 简单的前向Euler方法应用于SDE/ODE形式。类似于DDPM但用固定步长积分:从$x_t$直接加权更新到$x_{t-1}$,添加噪声以保持祖先采样(ancestral)性质。
数学表述(祖先版本): $$ x_{t-1} = x_t + \left( \mu_\theta(x_t, t) - x_t \right) \cdot \frac{\Delta t}{\sigma_t} + \sigma_{t-1} z, \quad z \sim \mathcal{N}(0, I) $$ 其中$\Delta t = 1$(离散步)。
DPM-Solver: 高阶数值求解器,将扩散过程视为常微分方程(ODE):$\frac{dx}{dt} = f(x, t)$,其中$f$由去噪网络隐式定义。使用Runge-Kutta-like方法(如2阶/3阶求解器)高效积分,加速采样。DPM-Solver++是其改进版,支持自适应步长和加速训练。
数学表述(简化2阶形式): $$ x_{t-1} = x_t + h \cdot f(x_t, t) + \frac{h^2}{2} \cdot \frac{df}{dt} $$ 其中$h = t - (t-1)$(时间步),$f(x_t, t) \approx -\frac{\epsilon_\theta(x_t, t)}{\sqrt{1 - \bar{\alpha}_t}}$(score函数形式)。
图像生成模型的VAE和视频生成模型的VAE有什么区别: 最大的区别在时间序列上的压缩。现在主流的3DVAE(CogVideox, hunyuan, wan2.1)在时间序列上有4倍的压缩。 视频VAE的核心挑战在于时空联合建模:既需捕捉单帧的空间细节,又需要建模帧间的时间动态。图像VAE则更注重高效的空间特征压缩与重建。
现在常用的评估生成质量的指标有哪些?在实践中认为这些指标准确吗,有什么更好的评估方案吗?
FID(Frechet Inception Distance) FID是用于评估生成图像与真实图像相似度的量化指标。它使用Inception网络将生成图像和真实图像转换为特征向量,假设这些特征向量的分布为高斯分布,并计算其均值和协方差矩阵。通过测量这两个高斯分布之间的“距离”来评估相似性,值越小,图像质量越高。
CLIP Score CLIP Score通过学习自然语言和图像对之间的语义关系来评估图像和文本的匹配度。它将自然语言和图像分别转换为特征向量,然后计算它们之间的余弦相似度。CLIP Score越高,图像和文本对之间的相关性越高。
Inception Score(IS) Inception Score评估生成图像的质量和多样性。它使用Inception网络对生成图像进行分类,正确分类结果越集中,质量越高。同时,当生成图像被分类为不同标签时,多样性越大。IS综合考虑了图像的质量和多样性,得分越高表示质量和多样性越好
CogVideoX的模型结构,3DVAE的压缩率,以及4F+1为什么要+1? CogVideoX 是一个基于扩散 Transformer 的文本到视频生成模型,能生成 10 秒连续视频。arxiv 模型采用了分层解耦设计:
- 文本编码器:处理文本提示
- 3D VAE(变分自编码器):视频压缩与解压
- 扩散 Transformer 主干:在压缩潜在空间进行去噪生成
- 专家 Transformer 架构:多模态融合与自适应处理
压缩率:CogVideoX 采用的 3D 因果变分自编码器(3D Causal VAE)的压缩比为 8×8×4。
3D VAE需要确保时间上的因果性(Causality),即当前帧的特征只能依赖于过去的帧,不能依赖未来的帧。 视频的第一帧通常作为初始参考帧被独立编码,不会与未来的帧发生混合,因此第一帧在隐空间中直接对应一个独立的隐式表示。而后续的视频帧则以4倍的下采样率在时间维度上下采样,即每4帧被压缩为一个隐式表示。
DDPM为什么预测噪声,而不是直接预测图像?
- $\epsilon$-predict和$x$-predict在数学本质上是一样的
- 在$t$较大时,输入更接近于纯噪声,SNR较低,此时$x$-predict预测的图像非常模糊,训练极其不稳定,而$\epsilon$-predict预测标准高斯噪声分布,这意味着神经网络的输出目标分布在整个训练过程中始终保持稳定且归一化。
- $\epsilon$-predict本质上等价于得分匹配,即预测指向真实数据流行高密度区域的方向
DDPM中的ELBO
DDPM的优化目标是最大化真实数据分布的对数似然 $\log{p_\theta(x_0)}$ $$ \log p_\theta(x_0) = \log p_\theta(x_0) = \log \int p_\theta(x_{0:T}) dx_{1:T} = \log \int q(x_{1:T}|x_0)\frac{p_\theta(x_{0:T})}{q(x_{1:T}|x_0)} dx_{1:T} $$ 通过Jensen 不等式,可以得到ELBO的下界: $$\log p_\theta(x_0) \ge \mathbb{E}_{q(x_{1:T} | x_0)} \left[ \log \frac{p_\theta(x_{0:T})}{q(x_{1:T} | x_0)} \right] = L_{VLB}$$
对ELBO各项代数代换,可以分解为三个部分:
- $D_{KL}(p_\theta(x_T)||q(x_T|x_0))$ 前向过程的最终状态和标准高斯先验之间的KL散度
- $D_{KL}(p_\theta(x_{t-1}|x_t)||q(x_{t-1}|x_t, x_0))$ 在已知真实数据分布的条件下的后验分布和神经网络预测得到的后验分布之间的KL散度,可以简化为两者均值的MSE
- $\log p_\theta(x_0|x_1)$ 重构项,表示从$x_1$生成$x_0$的对数似然
Noise scheduler的作用是决定在每一个时间步$t$,我们要想数据中注入多少比例的噪声以及保留多少比例的原始信号。
- DDPM中采用Linear noise scheduler,$\beta_t$从一个较小的值线性增加到一个较大的值,这样在前期时间步注入较少的噪声,后期时间步注入较多的噪声。
- Cosine Scheduler 通过一个平滑的余弦函数来定义 $\bar{\alpha}_t$,使得 SNR 的衰减更加平缓。这极大地改善了模型对图像细节的生成质量,尤其是在较低分辨率下表现极佳。
- Log-SNR 提出脱离时间步$t$,直接在噪声水平log-SNR上来定义调度。$\lambda_t = \log \text{SNR}(t) = \log \left( \frac{\bar{\alpha}_t}{1 - \bar{\alpha}_t} \right)$
- EDM 直接定义了一个独立的噪声分布 $p_{train}(\sigma)$ (EDM论文中使用对数正态分布, 让网络更多地关注中等噪声水平的数据)
Flow matching和DDPM的区别以及优势
- DDPM的前向过程是马尔可夫过程定义的,本质上是在做布朗运动,数据点$x_0$到纯噪声$x_t$的轨迹在空间中是一条弯曲的、充满扰动的曲线。而Flow matching的核心思想来自于连续归一化流和最优传输理论,以Rectified Flow为例,它将$x_0$到$x_t$定义为一条直线$x_t = t x_0+(1-t)z$,没有随机扰动的影响。
- 预测目标的区别:DDPM的网络在预测噪声或者说得分函数,而在Flow matching中预测的是状态$x_t$随时间$t$的导数,也就是速度$v_\theta(x_t, t)$
- Flow matching的优势:1. 在少步数下生成的图像质量更高 2. 不需要复杂的Noise scheduler,而只需要定义时间步采样策略
SD3中为什么要用两个CLIP和一个T5文本编码器
CLIP的编码器参数较小,只能生成粗粒度的文本,缺乏对复杂语法的理解能力,而T5拥有极强的上下文理解和语法解析能力,并且赋予了SD3的文字生成能力。
SD3中文本特征被划分为全局特征和细粒度特征。全局特征是两个CLIP的全局特征在特征维度上进行拼接,拼接后的全局文本向量与时间步嵌入相加,作为MM-DiT的条件注入;对于序列特征,首先将CLIP特征和T5特征映射到相同的维度,然后在token长度维度上进行拼接。
扩散模型蒸馏
- Progressive distillation:采用步数减半的迭代策略,假设教师模型需要走完2步,我们训练学生模型,让他在单步内直接预测教师模型走2步的结果。
- LCM:提出一致性模型,即在确定的PF-ODE轨迹上,任意两点$t$和$t’$都有$f_\theta(x_t, t) = f_\theta(x_{t’}, t’)$,并且满足边界条件$f_\theta(x_0, 0)=x_0$。LCM-LoRA将一致性蒸馏的损失函数仅仅反向传播到LoRA上: $$ \mathcal{L}_{CD}(\theta, \theta^-) = \mathbb{E} \left[ d\left( f_\theta(x_{t_{n+1}}, t_{n+1}), f_{\theta^-}(\hat{x}^{\phi}_{t_n}, t_n) \right) \right] $$
- ADD: 使用一个强大的教师扩散模型,利用SDS(Score distillation Sampling)来引导学生模型,保证文本与图像的语义对齐,同时引入一个判别器,判断学生模型单步生成的图像是否像真实、高清的图像。 $$ \nabla_\theta \mathcal{L}_{SDS} = \mathbb{E}_{t, \epsilon} \left[ w(t) (\epsilon_\phi(x_{\theta, t}, t, c) - \epsilon) \nabla_\theta x_\theta \right] $$ 将教师模型预测噪声的残差$(\epsilon_\phi-\epsilon)$当作一个伪梯度,直接推给学生模型。
Transformer基础知识
Transformer中QK点积为什么要除以$\sqrt{d_K}$?
在Transformer中,QK的点积结果会随着维度$d_K$的增加而变大,这可能导致softmax函数的输入值过大,从而使得softmax输出接近于0或1,导致梯度消失问题。通过除以$\sqrt{d_K}$,可以缩放点积结果,使其在合理的范围内,保持softmax的梯度稳定,从而提高模型的训练效果和性能。 将Q,K各维度分量视为均值为0,方差为1的独立同分布,QK内积的方差为$d_K$,为了保持方差,需要除以$\sqrt{d_K}$。
Multi-Head的作用
通过多个注意力头,可以关注不同子空间的特征,从而捕获到更加复杂的特征信息。
位置编码在Transformer中的作用 由于Attention模型f是全对称的,即对于任意的$m,n$,有: $$ f(\cdots, x_m, \cdots, x_n, \cdots) = f(\cdots, x_n, \cdots, x_m, \cdots) $$
这也意味着在模型看来,倒序的输入和正序的输入是一致的,但是对于语言输入来说,顺序是非常重要的,因此需要加入位置编码 $p_m, p_n$来引入位置信息。
常用的位置编码包括Sinusoidal位置编码和可学习的位置编码 Sinusoidal位置编码实现 $$ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) $$ $$ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) $$
1import torch 2import torch.nn as nn 3class SinusoidalEmbedding(nn.Module): 4 def __init__(self, d_model, max_seq_len = 512, base = 10000): 5 super().__init__() 6 self.d_model = d_model 7 self.base = base 8 self.max_seq_len = max_seq_len 9 # 生成一个形状为 (max_len, 1) 的位置索引矩阵 10 # 结果为 [[0.], [1.], [2.], ..., [max_len-1]] 11 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) 12 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) 13 14 pe[:, 0::2] = torch.sin(position * div_term) 15 pe[:, 1::2] = torch.cos(position * div_term) 16 17 pe = pe.unsqueeze(0) # (1, max_len, d_model) 18 19 # 使用 register_buffer 将其注册为模型的 buffer 20 # 这样它会随模型一起保存 (state_dict),但不会作为参数在反向传播中被更新 21 self.register_buffer('pe', pe) 22 23 def forward(self, x): 24 seq_len = x.size(1) 25 return x + self.pe[:, :seq_len, :]可学习位置编码实现:
1import torch 2import torch.nn as nn 3class LearnablePositionalEncoding(nn.Module): 4 def __init__(self, d_model: int, max_len: int = 196): 5 super().__init__() 6 self.pos_embedding = nn.Parameter(torch.randn(1, max_len, d_model) * 0.02) 7 8 def forward(self, x: torch.Tensor) -> torch.Tensor: 9 seq_len = x.size(1) 10 return x + self.pos_embedding[:, :seq_len, :]ROPE实现
1class RotaryEmbedding(nn.Module):
2 def __init__(self, hidden_size, num_heads, max_len=512, base=10000):
3 self.hidden_size = hidden_size
4 self.head_dim = hidden_size//num_heads
5 self.num_heads = num_heads
6 self.max_len = max_len
7 self.base = self.base
8 self.cos_pos_cache, self.sin_pos_cache = self._compute_embedding()
9
10 def _compute_embedding(self):
11 pos = torch.arrange(self.max_len).float()
12 theta_i = 1/ (self.base**(torch.arrange(0, self.head_dim, 2).float()/self.head_dim))
13 pos_emb = pos.unsqueeze(1)*theta_i.unsqueeze(0)
14
15 cos_pos = pos_emb.cos().repeat_interleave(2, dim=-1)
16 sin_pos = pos_emb.sin().repeat_interleave(2, dim=-1)
17 return cos_pos, sin_pos
18
19
20 def forward(self, q):
21 bs, seq_len = q.shape[0], q.shape[2]
22 cos_pos = self.cos_pos_cache[:seq_len].to(q.device)
23 sin_pos = self.sin_pos_cache[:seq_len].to(q.device)
24
25 cos_pos = cos_pos.unsqueeze(0).unsqueeze(0)
26 sin_pos = sin_pos.unsqueeze(0).unsqueeze(0)
27
28 q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)
29 q2 = q2.reshape(q.shape).contiguous()
30 return q * cos_pos + q2 * sin_pos
- LayerNorm, BatchNorm, InstanceNorm, GroupNorm之间的区别
LayerNorm:对每个样本的所有特征进行归一化(沿着(C, H, W)维度计算),适用于Transformer等序列模型,计算独立于批次大小。
BatchNorm:对每个特征在一个批次内进行归一化(沿着(B, H, W)维度计算),适用于卷积神经网络,依赖于批次大小。
InstanceNorm:对每个样本的每个特征进行归一化(沿着(H, W)维度计算),适用于风格迁移等任务,独立于批次大小。
GroupNorm:将特征分成多个组,对每个组进行归一化(沿着(C//num_groups, H, W)维度计算),适用于各种任务,独立于批次大小。
四种归一化方法的核心公式是一致的: $$ y = \frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}\gamma+\beta $$
RMSNormm是LayerNorm的一个变体,RMSNorm 的核心思想是在 LayerNorm 中,真正对稳定训练起决定性作用的是缩放,而不是平移。 $$ RMS(x) = \sqrt{\frac{1}{d}\sum_{i=1}^d x_{i}^{2}} $$ $$ y = \frac{x}{RMS(x)+\epsilon}\gamma $$
比较常见的LLM架构,例如Encoder-Only, Decoder-Only, Encoder-Decoder
Encoder-Only: 去掉了 Transformer 的生成部分,只保留了用于理解输入内容的部分。通过Masked language modeling方法训练,Bert
Decoder-Only:去除了专门的编码器,仅通过解码器来完成所有任务。采用了Causal Attention,每个token只能看到它自己和之前的token,不能看到未来的token。通过自回归的方式训练,即next-token prediction。GPT以及之后的大模型
Encoder-Decoder: 同时包含编码器和解码器两部分,编码器负责理解输入内容,解码器负责生成输出内容。编码器和解码器之间通过Cross-Attention进行信息交互。通过seq2seq的方式进行训练。
当前主流的架构是Decoder-Only,原因在于:1. scaling laws,研究发现,随着参数量和数据的增加,Decoder-Only 模型在“预测下一个词”这个简单任务上展现出了惊人的泛化能力(即“涌现能力”),足以覆盖几乎所有自然语言理解任务。2. 在底层算子优化、分布式训练以及推理加速方面更加高效。
手撕一下CLIP中InfoNCE Loss
1import torch
2import torch.nn.functional as F
3
4def InfoNCE_loss(image_feature, text_feature, logit_scale):
5 # 首先对image_feat和text_feat做L2 Norm,如果不做L2归一化,点积的结果可能会受到向量模长的影响,归一化将所有特征强行拉到一个超球面上,强制模型只能通过余弦相似度(向量夹角)来优化
6 image_feature_norm = F.normalize(image_feature, p=2, dim=-1)
7 text_feature_norm = F.normalize(text_feature, p=2, dim=-1)
8
9 # 余弦相似度计算
10 # logit_scale的作用:因为进行了归一化处理,余弦相似度的范围限制在[-1,1],输入到softmax中会导致softmax的输出分布会非常平缓,loss梯度较小,模型很难学习。通过logit_scale将其放缩,可以拉伸logits的数值范围,提供足够大的梯度帮助模型学习。
11 logits_per_image = logit_scale*image_feature_norm@text_feature_norm.T
12 logits_per_text = logits_per_image.T
13
14 # 将位于对角线上的特征作为label
15 batch_size = image_feature.shape[0]
16 labels = torch.range(batch_size, dtype = torch.long device = image_feature.device())
17
18 # 计算交叉熵损失
19 loss_image = F.cross_entropy(logits_per_image, labels)
20 loss_text = F.cross_entropy(logits_per_text, labels)
21
22 # 最终损失为图像和文本损失的平均。如果只算单向损失会丢失信息,在对比学习中,不同方向构建的负样本空间是不一样的。双向计算可以保证无论从哪个模态出发,联合潜空间的对齐都是致密的。
23 loss = (loss_image+loss_text)/2
24 return loss
强化学习
RLHF
RLHF包含三个标准阶段:
- 有监督微调(SFT),使用高质量的人工标注数据对预训练模型进行微调,使其具备基本的指令遵循能力;
- 训练奖励模型 (Reward Model, RM): * 给定一个输入提示(Prompt),让 SFT 模型生成多个不同的回答。人类标注员对这些回答进行排序(例如:回答 A > 回答 B)。使用这些偏好数据训练一个独立的奖励模型,使其能够像人类评委一样,为模型的输出打分;
- 强化学习优化(PPO算法): 将SFT模型作为策略网络,针对新的输入,策略网络生成回答,奖励模型对其进行打分,使用PPO算法,根据分数更新策略网络的参数,为了防止模型生成奇怪但高分的文本,会引入KL散度惩罚,确保优化后的模型不会偏离初始SFT模型太远。
DPO
DPO: 为了解决RLHF训练过于复杂,显存开销过大的问题,提出了DPO。基于Bradley-Terry偏好模型,将RLHF中的奖励函数和策略模型建立了一个解析关系,直接用策略模型本身的概率对数比来等价替换奖励值。 在 DPO 中,优化的目标函数被简化为一个优雅的分类损失(交叉熵): $$ \mathcal{L}_{DPO} = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)} \right) \right] $$ 其中 $y_w$ 是人类偏好的回答,$y_l$ 是被拒绝的回答,$\pi_\theta$ 是当前优化的模型,$\pi_{ref}$ 是冻结的参考模型,$\beta$ 是控制 KL 惩罚强度的温度超参数。
GRPO
GRPO: 是 DeepSeek 在其 DeepSeekMath 和 DeepSeek-R1 系列模型中广泛使用的创新算法。它的核心目的是在保持 PPO 性能的同时,大幅削减强化学习阶段的显存开销。在标准 PPO 中,为了计算优势函数(Advantage,即“这个动作比平均水平好多少”),需要训练一个与 Actor 体量相当的 Critic 模型(价值网络)来预测基线(Baseline)。GRPO 的核心创新在于彻底干掉了 Critic 模型。
- 组采样 (Group Sampling): 对于同一个输入提示 $x$,Actor 模型并行采样生成一组(Group)输出 ${y_1, y_2, \dots, y_G}$。
- 打分: 对这 $G$ 个输出分别计算奖励分数(可以使用外部的奖励模型,也可以使用代码编译器、数学公式验证器等基于规则的系统)。
- 相对优势计算: 不依赖 Critic 模型预测基线,而是直接在这一组生成结果内进行标准化(例如计算 Z-score)。分数高于组内平均值的回答获得正向 Advantage,低于平均值的获得负向 Advantage。
- 策略更新: 使用这些组内的相对优势来更新策略模型。