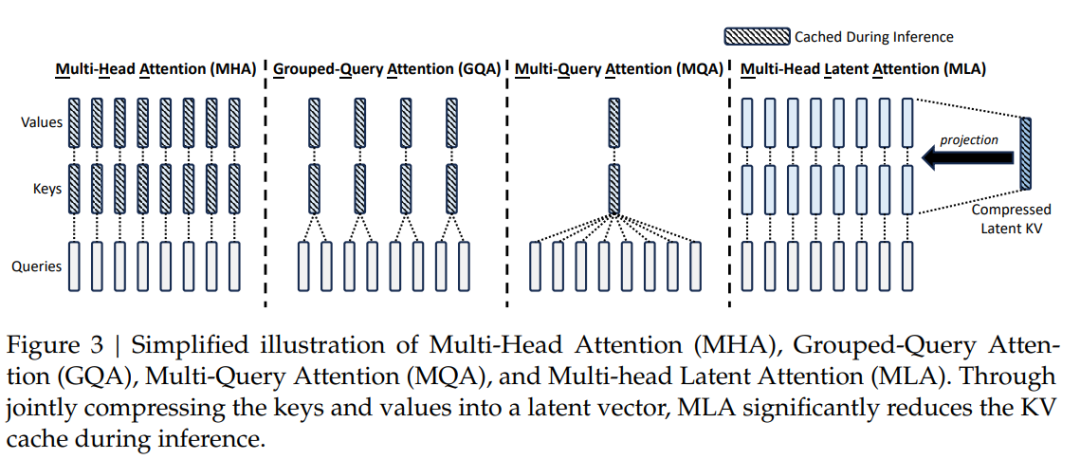
MHA (Multi-Head Attention)#
1import torch
2import torch.nn as nn
3
4class MultiHeadAttention(nn.Module):
5 def __init__(self, hidden_size, num_heads, drop_out = 0.0):
6 assert hidden_size % num_heads == 0
7 self.hidden_size = hidden_size
8 self.num_heads = num_heads
9 self.head_dim = hidden_size//num_heads
10
11 self.to_q = nn.Linear(hidden_size, hidden_size)
12 self.to_k = nn.Linear(hidden_size, hidden_size)
13 self.to_v = nn.Linear(hidden_size, hidden_size)
14
15 self.dropout = nn.Dropout(drop_out)
16 self.output = nn.Linear(hidden_size, hidden_size)
17
18 def forward(self, x, attention_mask = None):
19 B, L, C = x.shape
20
21 q = self.to_q(x).view(B,L,self.num_heads,self.head_dim).transpose(1,2) #[B, head, L, head_dim]
22 k = self.to_k(x).view(B,L,self.num_heads,self.head_dim).transpose(1,2)
23 v = self.to_v(x).view(B,L,self.num_heads,self.head_dim).transpose(1,2)
24
25 attention = torch.matmul(q, k.permute(0,1,3,2))/(self.head_dim**0.5) #[B, head, L, L]
26
27 if attention_mask is not None:
28 attention = attention.masked_fill(attention_mask[:,None,None,:]==0, float('-inf'))
29
30 attention = self.dropout(attention.softmax(dim=-1))
31 context = torch.matmul(attntion, v) #[B, head, L, head_dim]
32
33 context = context.transpose(1,2).contiguous().view(B, L, C) #[B, L, C]
34 out = self.output(context)
35 return out
MQA (Multi-Query Attention)#
1import torch
2import torch.nn as nn
3
4class MultiQueryAttention(nn.Module):
5 def __init__(self, hidden_size, num_heads, drop_out = 0.0):
6 assert hidden_size % num_heads == 0
7 self.hidden_size = hidden_size
8 self.num_heads = num_heads
9 self.head_dim = hidden_size//num_heads
10
11 self.to_q = nn.Linear(hidden_size, hidden_size)
12 self.to_k = nn.Linear(hidden_size, self.head_dim)
13 self.to_v = nn.Linear(hidden_size, self.head_dim)
14
15 self.dropout = nn.Dropout(drop_out)
16 self.output = nn.Linear(hidden_size, hidden_size)
17
18 def forward(self, x, attention_mask = None):
19 B, L, C = x.shape
20
21 q = self.to_q(x).view(B,L,self.num_heads,self.head_dim).transpose(1,2) #[B, head, L, head_dim]
22 k = self.to_k(x) # [B,L,head_dim]
23 v = self.to_v(x)
24
25 # 所有head共享k和v的参数
26 k = k.unsqueeze(1).expand(-1,self.num_heads,-1,-1)
27 v = v.unsqueeze(1).expand(-1,self.num_heads,-1,-1)
28
29 attention = torch.matmul(q, k.permute(0,1,3,2))/(self.head_dim**0.5) #[B, head, L, L]
30
31 if attention_mask is not None:
32 attention = attention.masked_fill(attention_mask[:,None,None,:]==0, float('-inf'))
33
34 attention = self.dropout(attention.softmax(dim=-1))
35 context = torch.matmul(attntion, v) #[B, head, L, head_dim]
36
37 context = context.transpose(1,2).contiguous().view(B, L, C) #[B, L, C]
38 out = self.output(context)
39 return out
GQA (Grouped-Query Attention)#
1import torch
2import torch.nn as nn
3
4class GroupedQueryAttention(nn.Module):
5 def __init__(self, hidden_size, num_heads, group_size = 2, drop_out = 0.0):
6 self.hidden_size = hidden_size
7 self.num_heads = num_heads
8 self.group_size = group_size
9 assert hidden_size % num_heads == 0
10 assert num_heads % group_size == 0
11
12 self.head_dim = hidden_size // num_heads
13 self.group_num = num_heads // group_size
14
15 self.to_q = nn.Linear(hidden_size, hidden_size)
16 # 分组
17 self.to_k = nn.Linear(hidden_size, self.head_dim*self.group_num)
18 self.to_v = nn.Linear(hidden_size, self.head_dim*self.group_num)
19
20 self.dropout = nn.Dropout(drop_out)
21 self.output = nn.Linear(hidden_size, hidden_size)
22
23 def forward(self, x, attention_mask = None):
24 B, L, C = x.shape
25
26 q = self.to_q(x).view(B, L, self.num_heads, self.head_dim).transpose(1, 2) #[B, head, L, head_dim]
27 k = self.to_k(x).view(B, L, self.group_num, self.head_dim).transpose(1, 2) # [B, groups, L, head_dim]
28 v = self.to_v(x).view(B, L, self.group_num, self.head_dim).transpose(1, 2) # [B, groups, L, head_dim]
29
30 # 每个组里共享同样的k,v
31 k = k.unsqueeze(2).expand(-1, -1, self.group_size, -1, -1).contiguous().view(B, -1, L, self.head_dim) # [B, heads, L, head_dim]
32 v = v.unsqueeze(2).expand(-1, -1, self.group_size, -1, -1).contiguous().view(B, -1, L, self.head_dim)
33
34 attention = torch.matmul(q, k.transpose(-1, -2)) / (self.head_dim**0.5)
35
36 if attention_mask is not None:
37 attention = attention.masked_fill(attention_mask[:,None,None,:]==0, float('-inf'))
38 attention = self.dropout(torch.softmax(attention, dim=-1))
39
40 context = torch.matmul(attention, v) # [B, heads, L, head_dim]
41 context = context.transpose(1,2).contiguous().view(B, L, C)
42
43 out = self.output(context)
44 return out
MLA(Multi-Head Latent Attention)#
1import torch
2import torch.nn as nn
3import math
4
5class RotaryEmbedding(nn.Module):
6 def __init__(self, hidden_size, num_heads, base=10000, max_len=512):
7 self.head_dim = hidden_size // num_heads
8 self.hidden_size = hidden_size
9 self.num_heads = num_heads
10 self.base = base
11 self.max_len = max_len
12 self.cos_pos_cache, self.sin_pos_cache = self._compute_pos_emb()
13
14 def _compute_pos_emb(self):
15 theta_i = 1./(self.base**(torch.arange(0, self.head_dim, 2).float()/ self.head_dim))
16 positions = torch.arange(self.max_len)
17 pos_emb = positions.unsqueeze(1)*theta_i.unsqueeze(0)
18
19 cos_pos = pos_emb.cos().repeat_interleave(2, dim=-1)
20 sin_pos = pos_emb.sin().repeat_interleave(2, dim=-1)
21 return cos_pos, sin_pos
22
23
24 def forward(self, q):
25 bs, seq_len = q.shape[0], q.shape[2]
26 cos_pos = self.cos_pos_cache[:seq_len].to(q.device)
27 sin_pos = self.sin_pos_cache[:seq_len].to(q.device)
28
29 cos_pos = cos_pos.unsqueeze(0).unsqueeze(0)
30 sin_pos = sin_pos.unsqueeze(0).unsqueeze(0)
31
32 q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)
33 q2 = q2.reshape(q.shape).contiguous()
34 return q * cos_pos + q2 * sin_pos
35
36class MultiHeadLatentAttention(nn.Module):
37 def __init__(self, hidden_size=256, down_dim=64, up_dim=128, num_heads=8, rope_head_dim=26, drop_out=0.0):
38 self.hidden_size = hidden_size
39 self.down_dim = down_dim
40 self.up_dim = up_dim
41 self.num_heads = num_heads
42 self.head_dim = hidden_size // num_heads
43 self.rope_head_dim = rope_head_dim
44 self.v_head_dim = up_dim // num_heads
45
46 # 降维投影
47 self.down_proj_kv = nn.Linear(hidden_size, down_dim)
48 self.down_proj_q = nn.Linear(hidden_size, down_dim)
49
50 # 升维投影
51 self.up_proj_k = nn.Linear(down_dim, up_dim)
52 self.up_proj_v = nn.Linear(down_dim, up_dim)
53 self.up_proj_q = nn.Linear(down_dim, up_dim)
54
55 # 解耦Q/K投影
56 self.proj_qr = nn.Linear(down_dim, rope_head_dim*num_heads)
57 self.proj_kr = nn.Linear(hidden_size, rope_head_dim)
58
59 # ROPE位置编码
60 self.rope_q = RotaryEmbedding(rope_head_dim*num_heads, num_heads)
61 self.rope_k = RotartEmbedding(rope_head_dim, 1)
62
63 # 输出
64 self.dropout = nn.Dropout(drop_out)
65 self.output = nn.Linear(num_heads*self.v_head_dim, hidden_size)
66 self.res_dropout = nn.Dropout(drop_out)
67
68 def forward(self, h, attention_mask = None):
69 B, L, C = h.shape
70
71 # step1: 低秩转换
72 c_t_kv = self.down_proj_kv(h) # [B, L, down_dim]
73 k_t_c = self.up_proj(c_t_kv) # [B, L, up_dim]
74 v_t_c = self.up_proj(c_t_kv)
75
76 c_t_q = self.down_proj_q(h) # [B, L, down_dim]
77 q_t_c = self.up_proj_q(c_t_q) # [B, L, up_dim]
78
79 # step2: 解耦Q/K处理
80 # RoPE投影处理
81 q_t_r = self.proj_qr(c_t_q).view(B,L, self.num_heads, self.rope_head_dim).transpose(1,2) # [B, num_heads, L, rope_head_dim]
82 q_t_r = self.rope_q(q_t_r)
83
84 k_t_r = self.proj_kr(h).unsqueeze(1) # [B, 1, L, rope_head_dim]
85 k_t_r = self.rope_k(k_t_r)
86
87 # step3: 注意力计算
88 q_t_c = q_t_c.view(B, L, self.num_heads, self.v_head_dim).transpose(1, 2)
89 q = torch.cat([q_t_c, q_t_r], dim=-1)
90
91 k_t_c = k_t_c.view(B, L, self.num_heads, self.v_head_dim).transpose(1, 2)
92 k_t_r = k_t_r.expand(-1, self.num_heads, -1, -1)
93 k = torch.cat([k_t_c, k_t_r], dim=-1)
94 v_t_c = v_t_c.view(B, L, self.num_heads, self.v_head_dim).transpose(1, 2)
95
96 scores = torch.matmul(q,k.transpose(-1,-2))/ (math.sqrt(self.head_dim) + math.sqrt(self.rope_head_dim))
97
98 if attention_mask is not None:
99 scores = scores.masked_fill(attention_mask[:,None,None,:] == 0, float('-inf'))
100 scores = self.dropout(torch.softmax(scores, dim=-1))
101 context = torch.matmul(scores, v_t_c)
102
103 context = context.transpose(1,2).contiguous().view(B, L, -1)
104 out = self.res_dropout(self.output(context))
105 return out