Preliminary Knowledge
条件概率公式
条件概率的一般形式:
$$ P(A,B,C)=P(C|B,A)P(B,A)=P(C|B,A)P(B|A)P(A) $$
$$ P(B,C|A)=P(C|B,A)P(B|A) $$
马尔可夫条件:下一状态的概率分布只能由当前状态决定,与前面的状态无关。
$$ P(A,B,C)=P(C|B)P(B|A)P(A) $$
$$ P(B,C|A)=P(C|B)P(B|A) $$
KL散度
KL散度是衡量两个概率分布之间差异的一种度量方法,它衡量了从一个分布到另一个分布所需的额外信息。KL散度的定义是建立在熵 Entropy 的基础上的,熵的定义如下:
$$ H(X)=-\sum_{i=1}^{n}p_i\log p_i $$
规定当 $p_i=0$ 时,$p_i\log p_i=0$
$$ H(p,q)=-\sum_{i=1}^{n}p(x)\log q(x) $$
在信息论中,交叉熵可认为是对预测分布 $q(x)$ 用真实分布 $p(x)$ 来进行编码时所需要的信息量大小。因此我们可以通过交叉熵和信息熵来推导相对熵(KL散度):
$$ \begin{align} KL(p\parallel q)&=H(p,q)-H(p) \\ &=-\sum_{i=1}^{n}p(x)\log q(x)+\sum_{i=1}^{n}p(x)\log p(x) \\ &=-\sum_{i=1}^{n}p(x)\log \frac{q(x)}{p(x)} \end{align} $$
KL散度的特点:
- 非对称性:$KL(p\parallel q)\neq KL(q\parallel p)$
- 非负性:$KL(p\parallel q)\geq 0$
如果固定$p(x)$,那么$KL(p\parallel q)=0 \Leftrightarrow p(x)=q(x)$。实际上这一点的证明要用到变分法,也是VAE中V的由来。
$$ \begin{align} p(x)&=\frac{1}{\sqrt{2\pi}\sigma_1}\exp\left({-\frac{(x-\mu_1)^2}{2\sigma_1^2}}\right) \\ q(x)&=\frac{1}{\sqrt{2\pi}\sigma_2}\exp\left({-\frac{(x-\mu_1)^2}{2\sigma_2^2}}\right) \end{align} $$
$$ \begin{align} \int p(x)\log(p(x))dx &= -\frac{1}{2}\left[1+\log(2\pi\sigma_1^2)\right] \\ \int p(x)\log(q(x))dx &= -\frac{1}{2}\log(2\pi\sigma_2^2)-\frac{\sigma_1^2+(\mu_1-\mu_2)^2}{2\sigma_2^2} \end{align} $$
$$ KL(p\parallel q)=\log\frac{\sigma_2}{\sigma_1}+\frac{\sigma_1^2+(\mu_1-\mu_2)^2}{2\sigma_2^2}-\frac{1}{2} $$
高斯分布的重参数化
若希望从高斯分布中采样,我们可以使用标准正态分布 $\mathcal{N}(0,1)$ 来采样 $z$,然后通过重参数化 $\sigma*z+\mu$ 的方式将其转换为高斯分布 $N(\mu,\sigma^2)$。
这样做的好处在于将随机性转移到了 $z$ 这个常量上,使得采样过程梯度可传播,从而可以使用梯度下降等优化算法进行训练。
生成模型
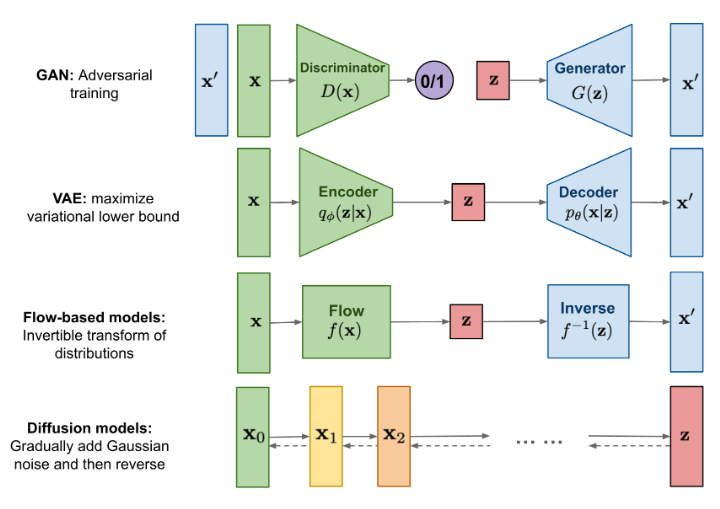
VAE
首先我们先回顾一下VAE在干什么:
我们有一批数据样本${x_1,x_2,…,x_n}$,对这个整体我们用$x$描述,我们的理想情况是得到$x$的分布$\tilde{p}(x)$,这样我们就可以直接根据$\tilde{p}(x)$来采样得到所有可能的$x$了,但是这显然很难实现。因此我们引入了$z$,$z$服从标准正态分布$\mathcal{N}(0,I)$,也就是说,我们可以先从标准正态分布中采样一个$z$,然后训练一个模型$q_{\theta}(x|z)$来算出$x$,用苏神的图解释该过程
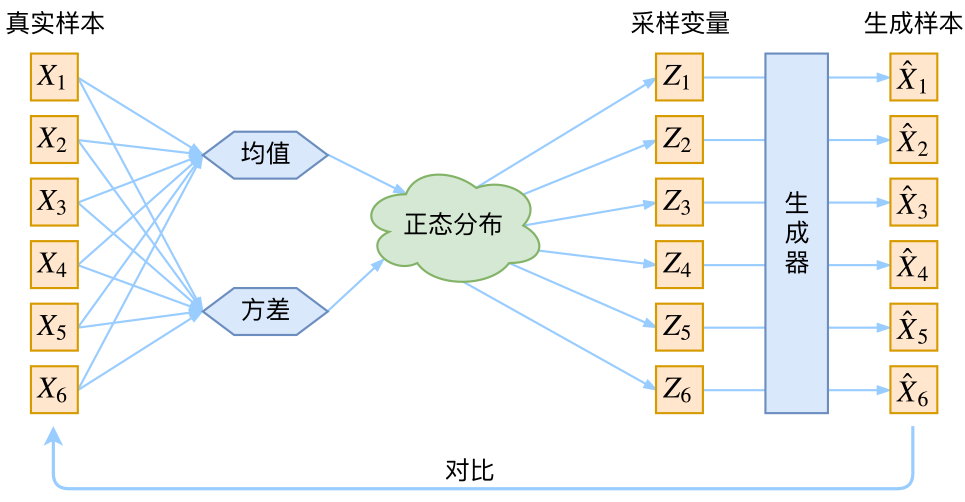
$$ q(x)=\int q_{\theta}(x|z)q(z)dz $$
$$ q(x, z)= q(x|z)q(z) $$
但是,实际上这个过程是存在问题的,我们并不清楚在标准正态分布中采样得到$z_{k}$是否对应原来的$x_{k}$,因此,我们不能简单地最小化$x_{k}$和$\hat{x}_{k}$之间的距离。
实际上在VAE中,我们假设的是后验分布$p(z|x)$为正态分布,也就是说,给定一个样本$x_k$,我们假设存在一个专属于$x_k$的分布$p(z|x_k)$,并且假设其为正态分布。这样我们从这个分布中采样出来的$z_k$可以确定是与$x_k$对应的。
那么如何得到这个专属的分布呢?既然已经假设他是一个正态分布了,那我们就只要知道他的均值$\mu$ 和方差$\sigma^2$就行了。怎么算均值和方差呢?那就用神经网络拟合出来吧!
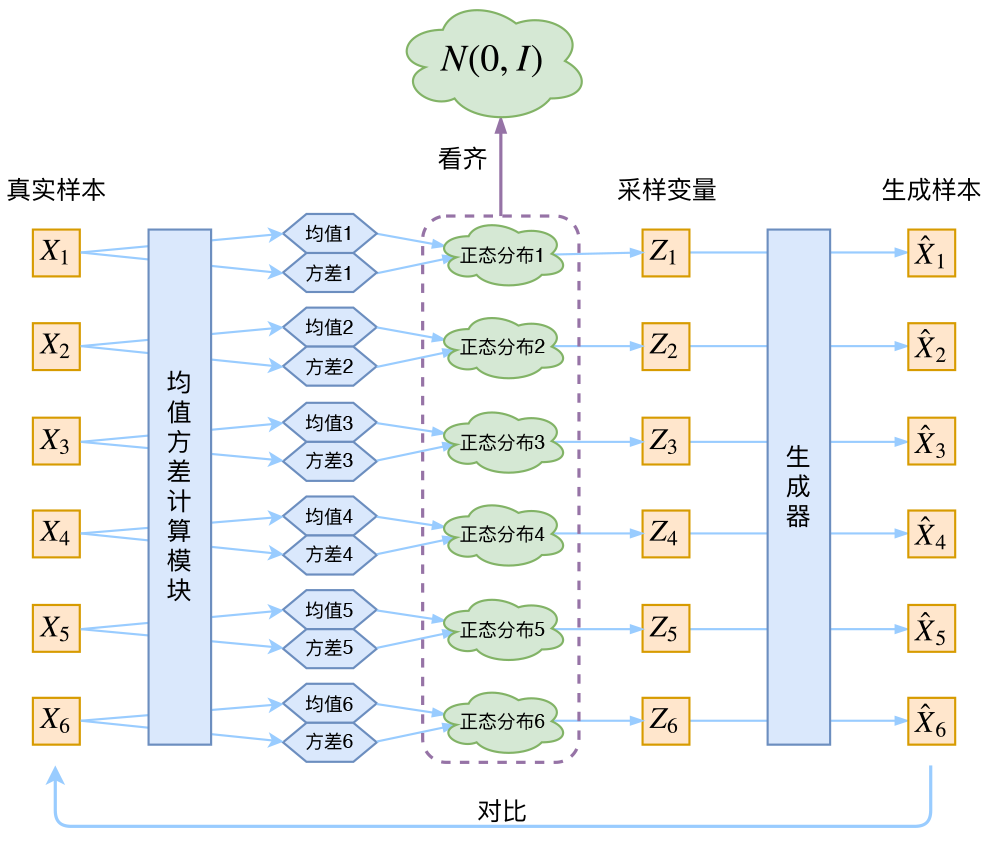
如何优化呢?我们的目标是希望$q(x)$能够逼近$\tilde{p}(x)$,这样的话就可以利用KL散度。具体来说,我们用$q(x,z)$来逼近$p(x,z)=\tilde{p}(x)p(z|x)$:
$$ KL(p(x,z)\parallel q(x,z)) = \int\int p(x,z)\ln\frac{p(x,z)}{q(x,z)}dzdx $$
$$ \begin{align} KL(p(x,z)\parallel q(x,z)) &= \int\tilde{p}(x)\left [\int p(z|x)\ln\frac{p(x,z)}{q(x,z)}dz\right ]dx \\ &=\mathbb{E}_{x\sim \tilde{p}(x)}\left [\int p(z|x)\ln\frac{p(x,z)}{q(x,z)}dz\right ] \end{align} $$
进一步省略$\tilde{p}(x)$带来的常数项:
$$ \mathcal{L} = KL(p(x,z)\parallel q(x,z)) = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\int p(z|x)\ln\frac{p(x|z)}{q(x,z)}dz\right] $$
再将 $q(x, z)= q(x|z)q(z)$ 代入,有:
$$ \mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)} \left [\mathbb{E}_{z\sim p(z|x)}[-\ln q(x|z)] + KL(p(z|x) \parallel q(z))\right ] $$
因此,我们目标就是优化 $q(x|z)$ 和 $q(z)$ 使得 $\mathcal{L}$ 最小化。
在代码实现过程中,$q(z)$ 假设为标准正态分布,$p(z|x),q(x|z)$ 分别对应Encoder和Decoder部分,都是未知的,这里我们都用神经网络来进行拟合。
首先对于 $p(z|x)$ ,我们假设其为均值为 $\mu(x)$,方差为 $\sigma^2(x)$ 的正态分布,$\mu(x)$ 和 $\sigma^2(x)$ 为输入为 $x$ ,输出为均值和方法的神经网络。因此loss中的KL散度项可以计算出来:
$$ KL(p(z|x)\parallel q(z)) = \frac{1}{2}\sum^{d}_{k=1}(\mu^2_{(k)}(x)+\sigma^2_{(k)}(x)-\ln\sigma^2_{(k)}(x)-1) $$
对于 $q(x|z)$ ,VAE论文给出了两种分布:伯努利分布以及正态分布,我们仍然以正态分布为例,仍然依靠神经网络估计均值和方差,$\tilde{\mu}(z)$,$\tilde{\sigma}^2(z)$,但是在这里我们通常会将方差固定为常数 $\tilde{\sigma}^2$ ,因此:
$$ -\ln q(x|z) \sim \frac{1}{2\tilde{\sigma}^2}||x-\tilde{\mu}(z)||^2 $$
在VAE中我们从 $p(z|x)$ 采样一个样本进行训练,那么也就是说:
$$ \mathcal{L} = \mathbb{E}_{x\sim \tilde{p}(x)}\left [-\ln q(x|z) + KL(p(z|x) \parallel q(z))\right ] $$
这样训练的loss也就能精确的计算出来了。
Diffusion Models
主要参考了Lil’s Log,苏神的生成扩散模型漫谈系列
DDPM
前向扩散过程(加噪)
Given a data point sampled form a real data distribution $x_0 \sim q(x)$, we define a forward diffusion process: we add small amount of Gaussian noise to the sample in $T$ steps, producing a sequence of noisy samples $x_1,…,x_T$. The step sizes are controlled by a variance schedule ${\beta_{t}\in(0,1)}_{t=1}^{T}$.
$$ \begin{align} q(x_t|x_{t-1}) &= \mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I) \\ q(x_{1:T}|x_0) &= \prod_{t=1}^{T}q(x_t|x_{t-1}) \end{align} $$
这里的前向过程可以视为马尔可夫过程,即当前状态$x_t$只与上一时刻的状态$x_{t-1}$有关。在给定上一状态$x_{t-1}$的条件下,获取第$t$步样本$x_t$的概率分布q(x_t|x_{t-1})。$\mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I)$ 表示给定上一步的状态$x_{t-1}$, $x_{t}$是一个以$\sqrt{1-\beta_t}x_{t-1}$为均值, $\beta_t I$为协方差的高斯分布的随机变量.
也就是说:$x_{t} = \sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_{t}}\epsilon_{t-1}, \epsilon_{t-1}\in\mathcal{N}(0,I)$
因此,当步数$t$逐渐增大时,采样数据$x_0$会逐渐趋向于纯高斯噪声
At any arbitrary time step $t$, we can sample $x_t$ in above process. Let $\alpha_{t} = 1-\beta_{t}$, $\bar{\alpha}_{t} = \prod_{i=1}^{t}\alpha_{i}$ and $\bar{\beta}_{t} = \sqrt{1-\bar{\alpha}_{t}^2}$:
$$ \begin{align} x_{t} &= \sqrt{\alpha_t}x_{t-1}+\sqrt{1-{\alpha}_{t}}\epsilon_{t} \\ \nonumber &=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t}\alpha_{t-1}}\epsilon_{t-2} \\ \nonumber &=… \\ \nonumber &=\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon \\ q(x_t|x_0) &= \mathcal{N}(x_t; \sqrt{\bar{\alpha}_{t}}x_{0}, (1-\bar{\alpha}_{t})I) \end{align} $$
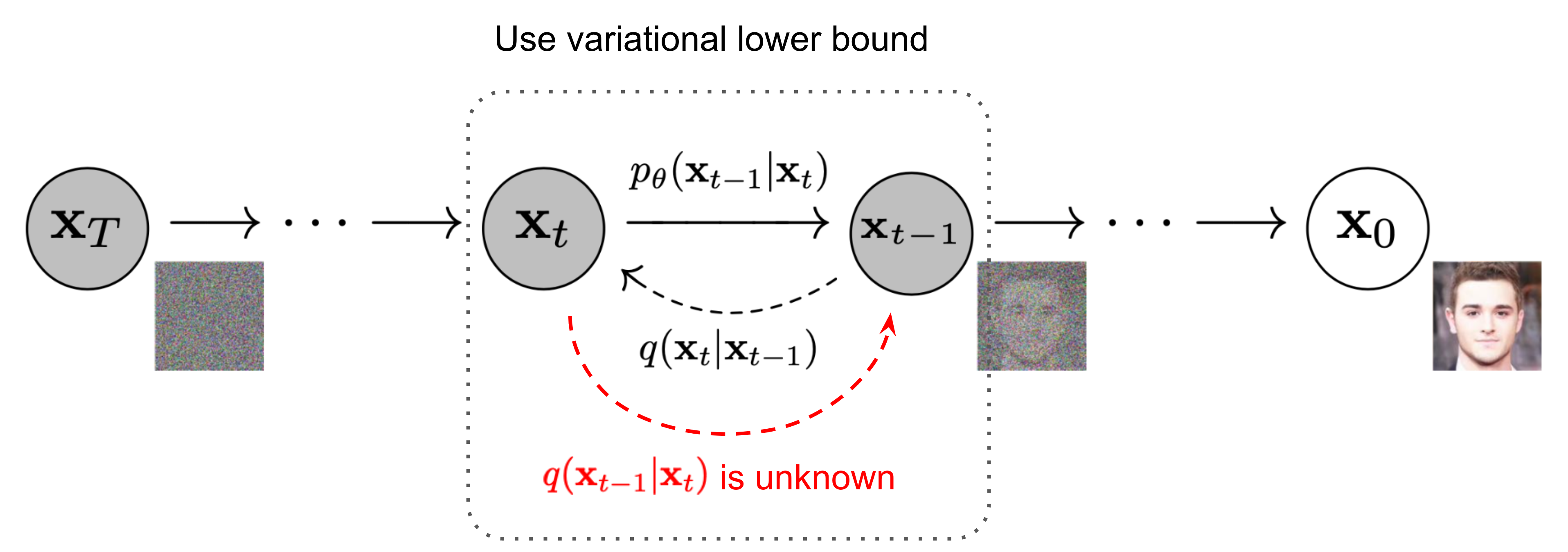
反向扩散过程(去噪)
If we can reverse the forward process and sample from $q(x_{t-1}|x_t)$, we will be able to recreate the true sample form a Gaussian noise input, $x_{T} \sim \mathcal{N}(0,I)$. Unfortunately, we cannot easily estimate $q(x_{t-1}|x_t)$ because it needs to use the entire dataset and therefore we need to learn a model $p_{\theta}$ to approximate these conditional probabilities in order to run the reverse diffusion process.
$$ \begin{align} p_{\theta}(x_{0:T}) &= p(x_T)\prod_{i=1}^{t}p_{\theta}(x_{t-1}|x_t) \\ p_{\theta}(x_{t-1}|x_t) &= \mathcal{N}(x_{t-1};\mu_{\theta}(x_t,t), \Sigma_{\theta}(x_t,t)) \end{align} $$
如何学习这一过程呢?最简单的方法就是最小化$x_{t-1}$和$p_{\theta}(x_{t-1}|x_t)$之间的欧式距离:
$$ ||x_{t-1}-p_{\theta}(x_{t-1}|x_t)||^{2} $$
继续细化这一过程,将前向过程可以改写为$x_{t-1}=\frac{1}{\sqrt{\alpha_t}}(x_t-\sqrt{1-\alpha_{t}}\epsilon_{t})$,因此模型$p_{\theta}$可以设计为:
$$ p_{\theta}(x_{t-1}|x_t) = \frac{1}{\sqrt{\alpha_t}}(x_t-\sqrt{1-\alpha_{t}}\epsilon_{\theta}(x_t,t)) $$
代入训练损失函数:
$$ ||x_{t-1}-p_{\theta}(x_{t-1}|x_t)||^{2} = \frac{\beta_{t}}{\alpha_t}||\epsilon_{t}-\epsilon_{\theta}(x_t,t)||^{2} $$
忽略常数系数 $\frac{\beta_{t}}{\alpha_t}$,然后代入 $x_{t} = \sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon$,最终得到的损失函数:
$$ ||\epsilon_{t}-\epsilon_{\theta}(\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon_{t},t)||^{2} $$
DDIM
我们也可以用贝叶斯重新认识DDPM的过程:
正向过程每一步是 $x_{t} = \sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_{t}}\epsilon_{t-1}, \epsilon_{t-1}\in\mathcal{N}(0,I)$,可以求出 $q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_{t}}x_{0}, (1-\bar{\alpha}_{t})I)$。DDPM要做的事就是从正向过程中求出反向过程所需要的 $q(x_{t-1}|x_t)$,这样就可以实现从任意 $x_T=z$ 出发,逐步采样出$x_{T-1}, x_{T-2}, …$ 一直到 $x_0$。
那么,根据贝叶斯定理,我们有:
$$ q(x_{t-1}|x_{t}) = \frac{q(x_{t}|x_{t-1})q(x_{t-1})}{q(x_t)} $$
我们不知道 $q(x_{t-1})$ 和 $q(x_t)$ 的表达式,但是我们知道的 $x_0$,因此我们可以将 $x_0$ 加入得到:
$$ q(x_{t-1}|x_{t}, x_0) = \frac{q(x_{t}|x_{t-1})q(x_{t-1}|x_0)}{q(x_t|x_0)} $$
这样公式的每一项我们都是已知的,所以上式是可以计算出来的:
$$ \begin{align} q({x}_{t-1}|{x}_t,{x}_0)=\mathcal{N}\left({x}_{t-1};\frac{\alpha_t\bar{\beta}_{t-1}^2}{\bar{\beta}_t^2}{x}_t+\frac{\bar{\alpha}_{t-1}\beta_t^2}{\bar{\beta}_t^2}{x}_0,\frac{\bar{\beta}_{t-1}^2\beta_t^2}{\bar{\beta}_t^2}{I}\right) \label{eq_backward} \end{align} $$
目前 $q({x}_{t-1}|{x}_t,{x}_0)$ 有两个依赖项$x_t, x_0$,但实际上 $x_0$ 是我们最终想要生成的结果,我们不能依赖 $x_0$。那么一个自然的想法是如果我们能够通过 $x_t$ 来预测 $x_0$,不就可以避免这一问题了吗?因此可以引入去噪模型 $\bar{\mu}(x_t)$ 来预测 $x_0$:
$$ \bar{\mu}(x_t) = \frac{1}{\bar{\alpha}_t}(x_t-\bar{\beta}_t\epsilon_{\theta}(x_t,t)) $$
代入 $\eqref{eq_backward}$,可以得到: $$ q({x}_{t-1}|{x}_t,{x}_0) \approx \mathcal{N}\left({x}_{t-1};\frac{1}{\alpha_t}\left(x_t-\frac{\beta_t^2}{\bar{\beta}_t}\epsilon_{\theta}(x_t, t)\right),\frac{\bar{\beta}_{t-1}^2 \beta_t^2}{\bar{\beta}_t^2}I\right) $$
虽然我们从单步正向过程 $q(x_t|x_{t-1})$ 一步步推导到 $q({x}_{t-1}|{x}_t,{x}_0)$,但是我们可以看到实际上结果与 $q(x_t|x_{t-1})$ 并没有什么关系,那么DDIM的思想就是在推导过程中舍弃掉 $q(x_t|x_{t-1})$。那么该如何求解 $q({x}_{t-1}|{x}_t,{x}_0)$ 呢?
DDIM提出用待定系数法求解,我们仍然假设 $q({x}_{t-1}|{x}_t,{x}_0)$ 为正态分布:
$$ \begin{align} q({x}_{t-1}|{x}_t,{x}_0) = \mathcal{N}\left(x_{t-1}; \kappa_{t}x_t+\lambda_{t}x_0, \sigma_{t}^2 I\right) \label{eq_ddim} \end{align} $$
并且该分布需要满足边际分布条件: $$ \int q({x}_{t-1}|{x}_t,{x}_0)q(x_t|x_0) = q(x_{t-1}|x_0) $$
想要满足该条件,其实只需要满足两个方程: $$ \begin{align} \bar{\alpha}_{t-1} &= \kappa_{t}\bar{\alpha}_{t}+\lambda_{t} \\ \bar{\beta}_{t-1} &= \sqrt{\kappa_{t}^2\bar{\beta}_{t}^2+\lambda_{t}^2} \end{align} $$
关于如何得到这两个方程,可以参考苏神生成扩散模型漫谈(四)

解这两个方程,可以得到 $\kappa_{t}$ 和 $\lambda_{t}$ 的表达式:
$$ \begin{align} \kappa_{t} &= \frac{\sqrt{\bar{\beta}_{t-1}^2-\sigma_t^2}}{\bar{\beta}_t} \\ \lambda_{t} &= \bar\alpha_{t-1}-\frac{\bar\alpha_t\sqrt{\bar{\beta}_{t-1}^2-\sigma_t^2}}{\bar{\beta}_t} \end{align} $$
可以代入 $\eqref{eq_ddim}$,同时将$x_0$替换为用$x_t$推导的形式(和DDPM一样),最终得到: $$ \begin{align} q(x_{t-1}|x_t) \approx \mathcal{N}\left({x}_{t-1};\frac{x_t-\bar\beta_t}{\alpha_t} \epsilon_{\theta}(x_t, t) + \sqrt{\bar\beta_{t-1}^2-\sigma_t^2}\epsilon_{\theta}(x_t, t),\sigma_t^2 I\right) \end{align} $$
随机微分方程(SDE)视角
从连续时间的角度来看,扩散模型可以被理解为随机微分方程(SDE)。这个视角由Score-based Generative Models提出,将离散的扩散过程推广到连续时间域。
前向SDE
当时间步趋于无穷小时,前向扩散过程可以表示为一个随机微分方程:
$$ dx=f(x,t)dt+g(t)dw $$
其中:
- $f(x,t)$是漂移系数(drift coefficient)
- $g(t)$是扩散系数(diffusion coefficient)
- $w$是标准布朗运动
对于DDPM,对应的SDE形式为:
$$ dx=-\frac{1}{2}\beta(t)x dt+\sqrt{\beta(t)}dw $$
其中$\beta(t)$是噪声调度函数。这个SDE描述了数据如何随时间逐渐变为纯噪声。
逆向SDE
Anderson (1982)证明了任何扩散过程都存在一个对应的逆向SDE,其形式为:
$$ dx=[f(x,t)-g(t)^2\nabla_x\log p_t(x)]dt+g(t)d\bar{w} $$
其中$\nabla_x\log p_t(x)$被称为得分函数(score function),$\bar{w}$是逆向时间的布朗运动。关键洞察是:如果我们知道每个时刻的得分函数,就可以从噪声逆向采样回数据。
得分匹配
扩散模型训练的本质是学习得分函数$\nabla_x\log p_t(x)$。通过Tweedie公式,我们可以证明:
$$ \nabla_x\log p_t(x_t)=-\frac{1}{\sqrt{1-\bar{\alpha}_t}}\mathbb{E}[\epsilon|x_t] $$
因此,训练网络预测噪声$\epsilon$等价于训练得分函数。训练目标可以写成:
$$ \mathcal{L}_{score}=\mathbb{E}_{t,x_0,\epsilon}\left[\lambda(t)|\nabla_x\log p_t(x_t)-s_\theta(x_t,t)|^2\right] $$
其中$s_\theta(x_t,t)$是神经网络预测的得分函数,$\lambda(t)$是权重函数。
概率流ODE
SDE视角的一个重要发现是,逆向SDE对应一个概率流ODE(Probability Flow ODE):
$$ dx=\left[f(x,t)-\frac{1}{2}g(t)^2\nabla_x\log p_t(x)\right]dt $$
这个ODE与SDE具有相同的边缘分布$p_t(x)$,但是确定性的。这解释了为什么DDIM的确定性采样是可行的,也为设计更高效的ODE求解器提供了理论基础。
SDE视角的优势
SDE框架带来了几个重要优势:
- 统一的理论框架: 可以在同一框架下理解DDPM、DDIM等不同变体
- 灵活的采样器: 可以使用各种SDE/ODE数值求解器,不局限于特定的离散化方案
- 可控生成: 通过在SDE中加入条件项,可以实现条件生成和可控编辑
- 理论分析: 连续时间框架使得理论分析(如收敛性、样本复杂度)更加容易
常见的SDE变体
基于SDE框架,研究者提出了多种扩散过程的设计:
- Variance Preserving (VP) SDE: 对应DDPM,保持数据方差
- Variance Exploding (VE) SDE: 对应于NCSN,添加噪声不做缩放,方差会爆炸
- Sub-VP SDE: 介于VP和VE之间的折中方案
这些不同的SDE设计在不同的应用场景中各有优势,为扩散模型的发展提供了丰富的工具箱。
UNet架构
UNet最初是为图像分割任务设计的编码器-解码器架构,在扩散模型中被广泛采用作为去噪网络的主干。
架构特点
- 编码器-解码器结构: 编码器逐步下采样提取特征,解码器逐步上采样恢复分辨率
- 跳跃连接: 在相同分辨率的编码器和解码器层之间建立直接连接,帮助保留细节信息
- 时间嵌入: 通过正弦位置编码将时间步$t$嵌入到网络中,指导去噪过程
- 注意力机制: 在较低分辨率层引入自注意力层,捕捉长程依赖关系
在扩散模型中的应用
UNet在DDPM、Stable Diffusion等模型中作为核心组件,输入是噪声图像$x_t$和时间步$t$,输出是预测的噪声$\epsilon_\theta(x_t,t)$。网络通过残差块、归一化层和注意力层的组合,学习从噪声中恢复数据的过程。
优势与局限
- 优势: 归纳偏置适合图像数据,跳跃连接有效传递信息,在像素空间效果优异
- 局限: 计算复杂度随分辨率平方增长,难以直接扩展到高分辨率图像,缺乏transformer的灵活性
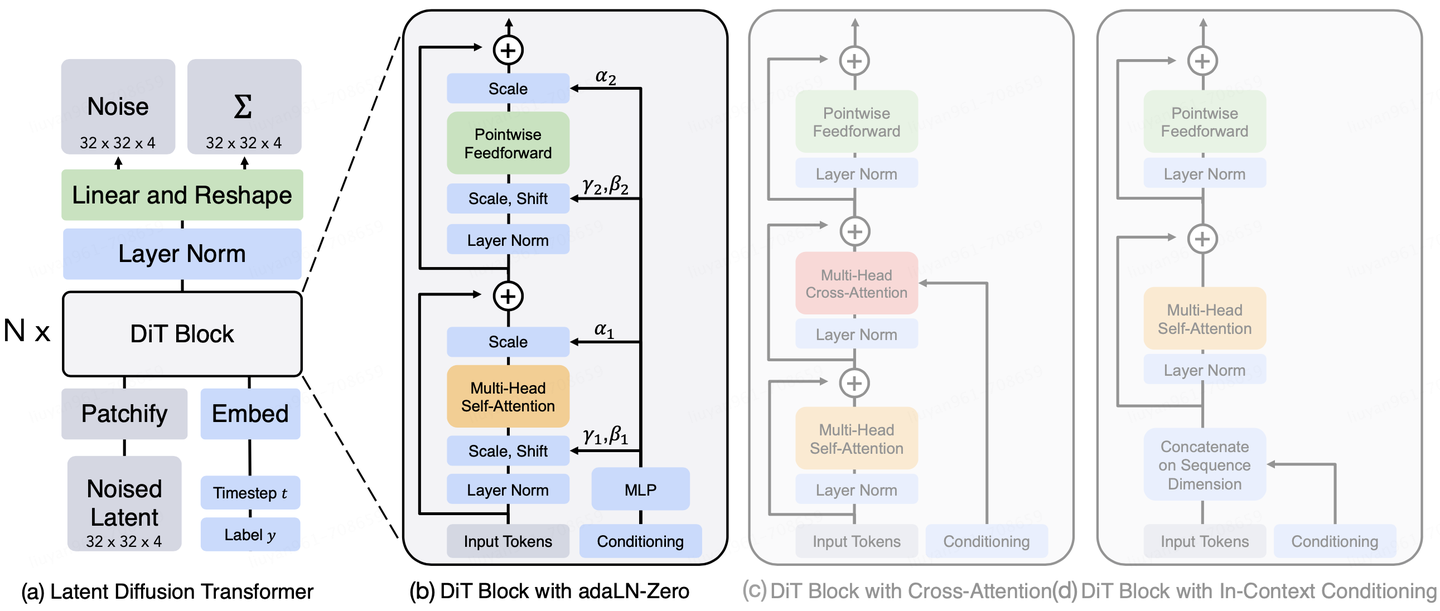
DiT(Diffusion Transformer)
DiT用纯Transformer架构替代UNet,将图像视为patch序列进行处理,代表了扩散模型架构设计的新方向。
核心设计
- Patchify: 将图像分割成固定大小的patch(如16×16),每个patch通过线性投影得到token
- Transformer块: 使用标准的多头自注意力和前馈网络,处理patch序列
- 条件注入: 时间步$t$和类别标签通过adaptive layer norm (adaLN)注入到每个transformer块中
- 输出层: 最后将token序列重组回图像空间,预测噪声或速度场
adaLN调节机制
DiT的关键创新是adaLN,它根据时间步和条件调节transformer的归一化参数:
$$ \text{adaLN}(h,c)=\gamma(c)\cdot\frac{h-\mu(h)}{\sigma(h)}+\beta(c) $$
其中$c$是条件嵌入,$\gamma(c)$和$\beta(c)$是由条件预测的缩放和偏移参数。这种设计使得条件信息能够有效地调节整个网络的行为。
扩展性优势
DiT展现了优异的扩展性:
- 模型大小: 可以轻松扩展到数十亿参数,遵循transformer的扩展规律
- 性能提升: 更大的模型和更多的计算带来持续的性能改进
- 灵活性: 统一的架构便于迁移学习和多模态扩展
与UNet的对比
- 归纳偏置: UNet内置空间归纳偏置,DiT更依赖数据学习
- 计算效率: 小规模时UNet更高效,大规模时DiT扩展性更好
- 应用场景: UNet适合像素空间,DiT在latent空间和高分辨率生成中表现优异
条件生成
条件生成是扩散模型的重要应用方向,通过在生成过程中引入额外的条件信息(如文本、类别标签、图像等),可以实现可控的内容生成。
采样引导
分类器引导(Classifier Guidance)
分类器引导通过在采样过程中使用一个预训练的分类器来引导生成过程。具体来说,在每个去噪步骤中,除了使用扩散模型预测的噪声外,还加入分类器梯度的引导:
$$ \tilde{\epsilon}_{\theta}(x_t,t,y)=\epsilon_\theta(x_t,t)+s\cdot\nabla_{x_t}\log p_\phi(y|x_t) $$
其中$y$是条件标签,$s$是引导强度,$p_\phi(y|x_t)$是分类器。更大的$s$会产生更符合条件的样本,但可能损失多样性。
无分类器引导(Classifier-Free Guidance)
无分类器引导通过在训练时同时学习条件和无条件模型来避免使用额外的分类器。在训练过程中,以一定概率$p$丢弃条件信息,在采样时通过以下方式组合两者的预测:
$$ \tilde{\epsilon}_{\theta}(x_t,t,y)=\epsilon_\theta(x_t,t,\emptyset)+w\cdot(\epsilon_\theta(x_t,t,y)-\epsilon_\theta(x_t,t,\emptyset)) $$
其中$w$是引导权重,$\emptyset$表示无条件。当$w=0$时退化为无条件生成,$w>1$时会增强条件的影响。
模型架构层面的信息注入
Cross-Attention
对于文本到图像生成等任务,常用的方法是将文本编码器(如CLIP text encoder)的输出通过交叉注意力机制注入到UNet或DiT中。具体来说,图像特征作为查询(Q),文本特征作为键(K)和值(V),通过注意力机制实现条件信息的融合。
AdaLN-Zero
DiT中的AdaLN-Zero是一种改进的条件注入机制,通过将adaLN的缩放参数$\gamma$初始化为零,使得模型在训练初期表现为恒等映射。这种设计提高了训练稳定性,使得大规模DiT模型更容易收敛,并且能够更有效地学习条件信息的影响。
In-Context condition
In-Context条件生成是一种新兴的条件注入方式,通过在输入序列中提供示例来隐式地传达生成意图。与显式的文本提示或类别标签不同,这种方法允许模型从上下文中学习任务和风格。例如,在图像生成中,可以将参考图像作为prefix tokens添加到输入序列中,模型通过注意力机制理解参考图像的风格和内容,从而生成风格一致的新图像。
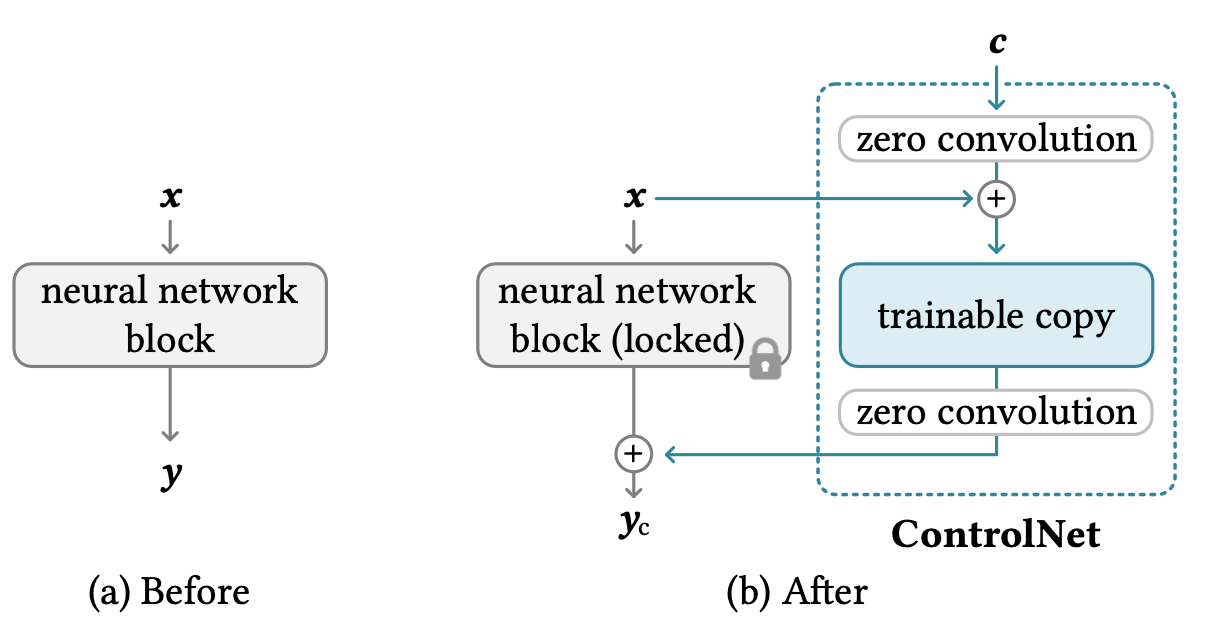
ControlNet
ControlNet是一种为预训练扩散模型添加空间条件控制的方法,通过冻结原始模型并添加可训练的副本来实现。它将边缘图、深度图、姿态等结构信息转换为像素级的控制信号,注入到UNet的各个层中。锁定原始 UNet 权重,复制一份 Encoder 的权重作为ControlNet 分支。将条件 y 输入ControlNet,通过零卷积层(Zero Convolution)逐渐将特征加回到原始 UNet 的 Decoder 中。
扩散模型加速与蒸馏
Training-free(改进采样算法,减少采样步数):
- DDIM: 通过非马尔可夫过程实现确定性采样,可以用更少的步数(如50步)达到相近的质量
- DPM-Solver: 基于概率流ODE设计的高阶求解器,在10-20步内就能生成高质量样本
- EDM: 通过优化噪声调度和采样策略,进一步提升采样效率
Training:
- Progressive Distillation: 逐步将N步采样蒸馏到N/2步,递归进行直到达到期望的步数(如4步或1步)
- Consistency Models: 训练模型直接将任意时刻的噪声样本映射到数据,实现单步生成