Daily Paper 003 第三天!!🥳
Title: Image Super-resolution with Text Prompt Diffusion (ArXiv 2024)
code(并未开源)
Introduction
在真实应用中,场景往往存在复杂多样的退化类型,现有的方法大部分都是在已知退化类型(双三次下采样)的数据上进行训练的,因此在推理的时候效果往往不好。常用的解决方法是盲超分方法,大致可以分为三类:
Explicit Methods 通常依赖于预定义的退化模型。它们将降解参数(如模糊核或噪声)作为 SR 模型的条件输入进行估计。预定义的退化模型限制了退化表示的范围,从而限制了方法的通用性。 Implicit Methods 通过广泛的外部数据集来捕捉潜在的降解模型。它们通过利用真实捕获的 HR-LR 图像对或 HR 和未配对的 LR 数据来学习数据分布,从而实现这一目标。但是学习数据分布具有一定的挑战性,效果并不理想。 定义复杂退化,合成大量数据用于训练。为了模拟真实世界的退化,这些方法将退化分布设置得足够广泛。然而,这增加了 SR 模型的学习难度,并不可避免地导致性能下降。 总体来说,对于SR来说,退化模型的建模尤为重要。但是现有的方法都局限于从LR输入上获取退化信息,表征能力有限。一种方法是引入额外信息,比如参考先验[Robust referencebased super-resolution via c2-matching]和生成先验[Glean: Generative latent bank for large-factor image super-resolution, Gan prior embedded network for blind face restoration in the wild]。文章提出了引入text prompt作为先验,其好处在于:
- 文本信息本身具有灵活性,适用于各种情况
- 可以利用当前的预训练视觉语言模型的强大功能
- 文本引导可作为SR的补充信息
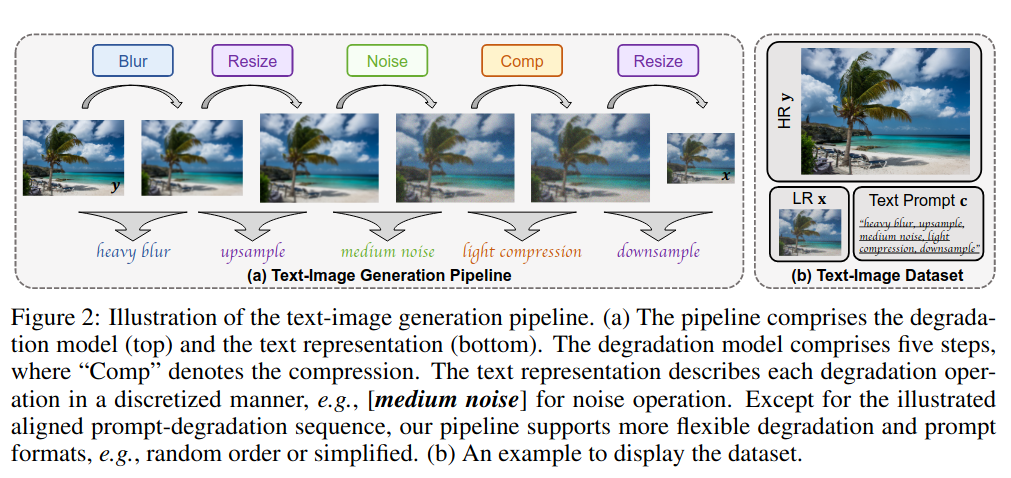
文章提出了一个用于SR退化模型的文本-图像的生成模型。用Text Prompt来表示退化以提供额外的先验信息 (这里作者说LR图像可以提供与内容相关的低频信息和语义信息,因此不需要整体图像的描述。我觉得LR图像确实表达了部分低频信息和语义信息,但是加入全局的caption会不会更好一点)。然后用binning method[Crafting training degradation distribution for the accuracy-generalization trade-off in real-world super-resolution]对退化分布进行分区,然后对每个分区进行文字描述后合并,得到最终的text prompt。
然后进一步提出了PromptSR方法,利用预训练的语言模型充当文本编码器,将Text Prompt映射到嵌入序列中。然后,扩散模型以LR图像和文本嵌入为条件,生成相应的HR图像。
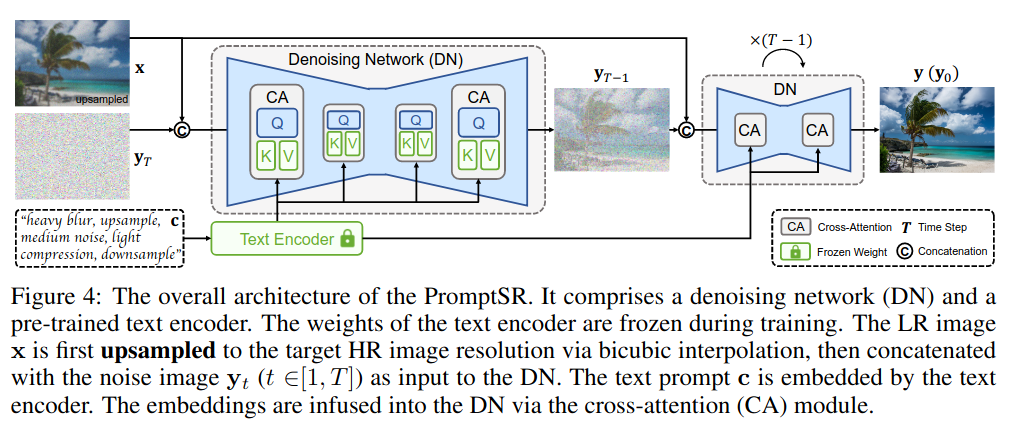
Experiment
Dataset: 适用LSDIR作为训练数据,包括84,991张高分辨率数据,利用文章的方法生成文本-数据对。
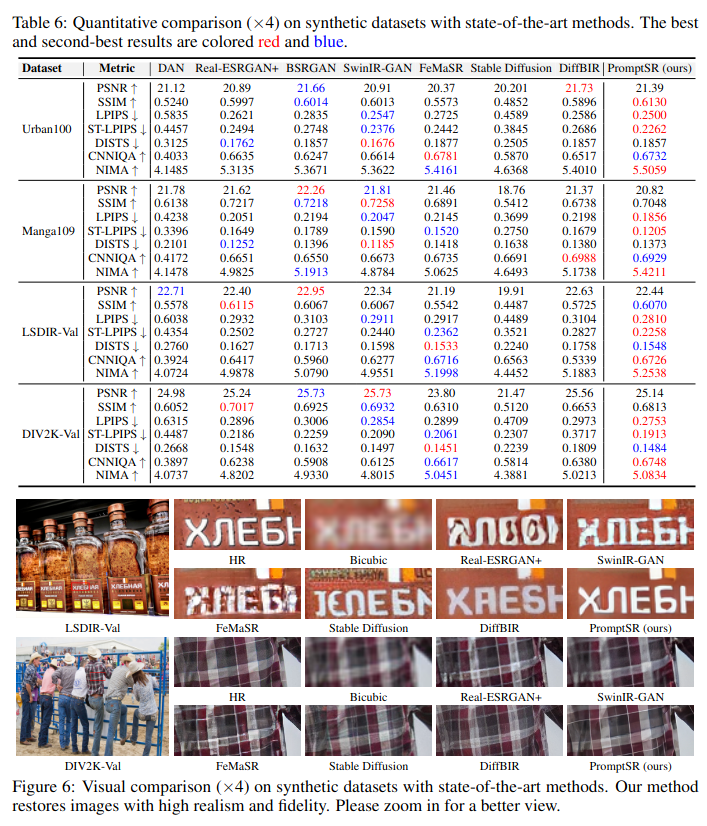
具体的实验结果可以参考原论文:
总结
我觉得这类基于扩散模型微调的图像复原网络基本上都是基于SD的,网络结构上的差异不会太大。创新点主要集中于生成degradation的pipe,以及如何利用SD中的文本能力。 这篇文章的主要创新点就在于将图像的退化类型作为文本信息输入扩散模型中,文章也并未开源,可以略作参考。